As an open data fan or as someone who is just looking to learn how to publish data on the Web and distribute it through the Semantic Web you will be facing the question “How to describe the dataset that I want to publish?” The same question is asked also by people who apply for a publicly funded project at the European Commission and want to have a Data Management plan. Next we are going to discuss possibilities which help describe the dataset to be published.
The goal of publishing the data should be to make it available for access or download and to make it interoperable. One of the big benefits is to make the data available for software applications which in turn means the datasets have to be machine-readable. From the perspective of a software developer some additional information than just name, author, owner, date… would be helpful:
- the condition for re-use (rights, licenses)
- the specific coverage of the dataset (type of data, thematic coverage, geographic coverage)
- technical specifications to retrieve and parse an instance (a distribution) of the dataset (format, protocol)
- the features/dimensions covered by the dataset (temperature, time, salinity, gene, coordinates)
- the semantics of the features/dimensions (unit of measure, time granularity, syntax, reference taxonomies)
To describe a dataset the best is always to look first at existing standards and existing vocabularies. The answer is not found looking only at one vocabulary but at several.
Data Catalog Vocabulary (DCAT)
DCAT is an RDF Schema vocabulary for representing data catalogs. It is an RDF vocabulary for describing any dataset, which can be standalone or part of a catalog.
Vocabulary of Interlinked Datasets (VoID)
VoID is an RDF vocabulary, and a set of instructions, that enable the discovery and usage of linked data sets. VOID is an RDF vocabulary for expressing metadata about RDF datasets.
Data Cube vocabulary
Data Cube vocabulary is focused purely on the publication of multi-dimensional data on the web. It is an RDF vocabulary for describing statistical datasets.
Asset Description Metadata Schema (ADMS)
ADMS is a W3C standard developed in 2013 and is a profile of DCAT, used to describe semantic assets.
You will find only partial answers of how to describe your dataset in existing vocabularies while some aspects are missing or complicated to express.
- Type of data – there is no specific property for the type of data covered in a dataset. This value should be machine readable which means it should be standardized, possibly to an URI which can be de-reference-able to a thing. And this ‘thing’ should be part of an authority list/taxonomy which is not existing yet. However one can use the adms:representationTechnique, which gives more information about the format in which a dataset is released. This points only to dcterms:format and dcat:mediaType.
- Technical properties like – format, protocol etc.
There is no property for protocol and again these values should be machine-readable, standardized possibly to an URI.
VoID can help with the protocol metadata but only for RDF datasets: dataDump, sparqlEndpoint. - Dimensions of a dataset.
- SDMX defines a dimension as “A statistical concept used, in combination with other statistical concepts, to identify a statistical series or single observations.” Dimensions in a dataset can therefore be called features, predictors, or variables (depending on the domain). One can use dc:conformsTo and use a dc:Standard if the dataset dimensions can be defined by a formalized standard. Otherwise statistical vocabularies can help with this aspect which can become quite complex. One can use the Data Cube vocabulary specifically qd:DimensionProperty, qd:AttributeProperty, qd:MeasureProperty, qd:CodedProperty in combination with skos:Concept and sdmx:ConceptRole.
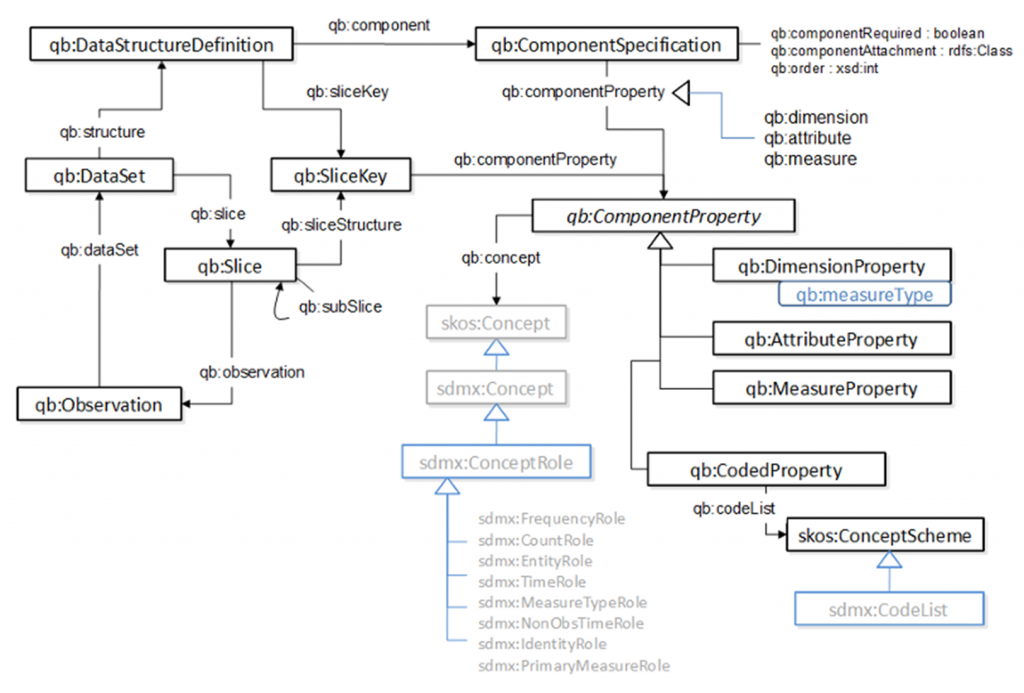
- SDMX defines a dimension as “A statistical concept used, in combination with other statistical concepts, to identify a statistical series or single observations.” Dimensions in a dataset can therefore be called features, predictors, or variables (depending on the domain). One can use dc:conformsTo and use a dc:Standard if the dataset dimensions can be defined by a formalized standard. Otherwise statistical vocabularies can help with this aspect which can become quite complex. One can use the Data Cube vocabulary specifically qd:DimensionProperty, qd:AttributeProperty, qd:MeasureProperty, qd:CodedProperty in combination with skos:Concept and sdmx:ConceptRole.
- Data provenance – there is the dc:source that can be used at dataset level but there is no solution if we want to specify the source at data record level.
In the end one needs to combine different vocabularies to best describe a dataset.
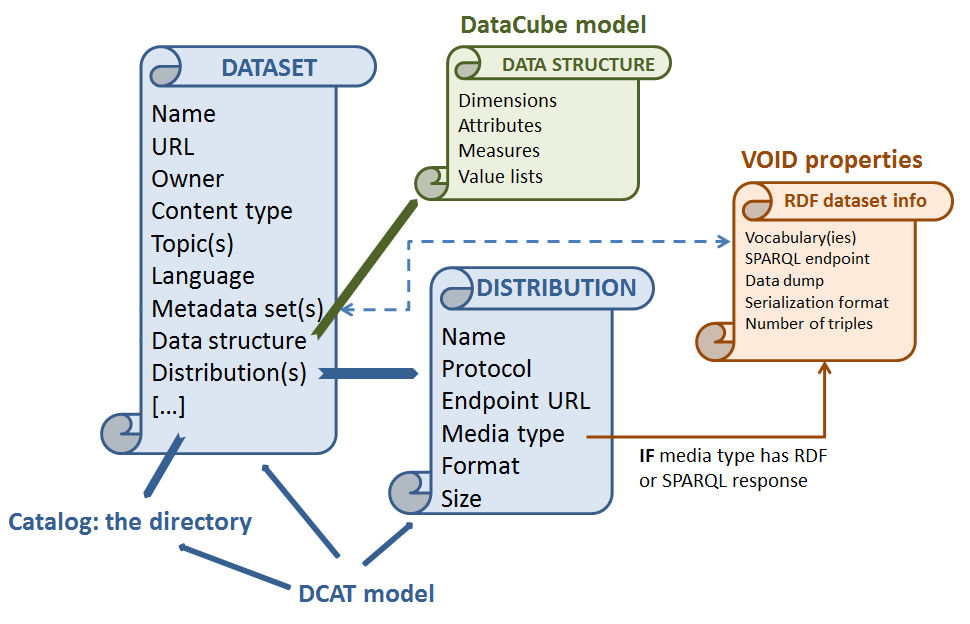
The tools out there used for helping in publishing data seem to be missing one or more of the above mentioned parts.
- CKAN maintained by the Open Knowledge Foundation uses most of DCAT and doesn’t describe dimensions.
- Dataverse created by Harvard University uses a custom vocabulary and doesn’t describe dimensions.
- CIARD RING uses full DCAT AP with some extended properties (protocol, data type) and local taxonomies with URIs mapped when possible to authorities.
- OpenAIRE, DataCite (using re3data to search repositories) and Dryad use their own vocabularies.
The solution to these existing issues seem to be in general, introducing custom vocabularies.
References:
- Valeria Pesce, “How to describe a dataset. Interoperability issues”, Presentation at the Global Forum on Agricultural Research, 21.09.2015
-
DataCube: http://www.w3.org/TR/vocab-data-cube/
-
OpenAIRE: https://www.openaire.eu/
-