When I sometimes (still) get to talk about my motivation to spend quite a lot of my free time on volunteering I always start with: I’ve been volunteering since I started University. I’ve been involved in different communities since 2007, for more than 11 YEARS!
When I get asked WHY?… Honestly, nowadays, it is simply because: this is what I know to do! In my free time, I am used to. going to organizer meetings, be volunteer responsible at a conference, take care of conference registration, make sure speakers are introduced or evolve partnerships and bring in sponsors and most important mentor/motivate/empower people… (these are the usual, these days).
However, I want to take this opportunity and present my volunteering CV (which I was postponing for years to do) and ALL the trainings and skills I gathered in 11 years. These are points, which in my CV, land under hobbies or I mention only maybe 25% of them as social skills. Why? Because a CV should not be longer than 1-2 pages, maximum 3! Also because, too little, HR people looking for developers/engineers are interested that you live a double life. Usually this is mentioned, by me, in face to face interviews when required. Do you have better suggestions?
My volunteering CV (about my second life) 😉
2012 Nov. – present days – member of GDG Vienna
My biggest achievement in GDG Vienna is creating the Women Techmakers Vienna community. This is the 6th year since it exists and a lot of people appreciate us and like what we stand for: Equality & diversity in STEM regardless of gender. Community builder, people empowering and networking are key skills that helped me achieve this together with like-minded people I met through GDG (locally and globally).
I was organizer of DACH level tech conference DACHfest.
I was 6 times organizers of DevFest Vienna.
And I organized numerous meetups and delivered tech and social content.
Vienna Summer Course 2011 project – I was main organizer of one of the biggest projects which bring, yearly, to Vienna, around 20-25 European students from other different technical universities to share culture and knowledge. I was leading a team of 6 people making sure the event happens on time and in the budget and that team members, participants and professors are happy (all stakeholders).
Board member – HR responsible – board membership is a year long engagement. Along with 6 other dedicated persons on dedicates roles, we devised and executed the strategic plan meant to create and leave a local sustainable organization while leading by the European level vision: “Empowered diversity“. My responsibility was recruiting, motivating and empowering community members.
I was involved in numerous other local projects over the years and towards the end I was more in a mentor role. Now I am proud BEST Vienna ALUMNA.
2007 Oct. – 2011 June – member of AIESEC Cluj-Napoca
IT Challenge project – while in AIESEC I was a participant and main organizer of IT Challenge. The project was bringing technical students closer to tech companies who offered case-studies to be solved by participants. At the 3rd edition of the project I was leading my own team of 5 people and making sure we are reaching our goals. I learned project management, team leading and about motivating volunteering student. It also brought me my first tech internship at NOKIA R&D in Cluj-Napoca.
I was also an aspiring trainer and “graduated” while delivering content at the biggest Romanian intercultural preparation seminar conference, which had over 400 participants (if I remember correct, were probably even more..)
On my road of becoming a ‘change agent‘ I took part in a AIESEC internship done at the Technical University of Graz, Austria. Which changed my life!
Now I am proud ALUMNA of AIESEC Cluj-Napoca
In the next post I will mention the numerous trainings and content I had the opportunity to be exposed to due to these volunteering opportunities.
I am writing a piece about transactions because the subject of transactions sounds so heavy standalone and also because I recently had to recall all the theory from university about it. And surprise surprise, real life software behaves/looks different than in the theory. So, if you are looking to refresh your knowledge and also get the bullet points to simply solidify knowledge keep reading… (at least the bullet points).
“Transaction processing is information processing in computer science that is divided into individual, indivisible operations called transactions. Each transaction must succeed or fail as a complete unit; it can never be only partially complete.”
“Transaction processing is designed to maintain a system’s Integrity in a known, consistent state, by ensuring that interdependent operations on the system are either all completed successfully or all canceled successfully.” Wikipedia
Only reading the definition of transactions we are remembered of the correct way of using them and what the goal should be:
indivisible operations
succeed or fail as a complete unit
maintain a system’s integrity
We got this on our agenda so lets turn to the technicalities of it.
A good example, which occurs most in real life software, is the work with databases. Databases should have a build in mechanism to tap into their transactional usage either automatic – it takes care on its own on these – or more “manual” – it is up to the developer to decide when the transaction starts and ends. Find out in the design and requirements phase, which scenario you need. Set the parameter of the database correct:
database auto-commit true or false
I want to focus on the database.autoCommit(false) scenario next because we differentiate between actions. On some actions transactions are not necessary.
Just because I have to mention: a reliable transactional system must comply to the ACID criteria to be good (atomicity, consistency, isolation, and durability). When you use a transactional system you just need to know that you can rely on ADIC criteria but you do not need to be concerned with each one of them in depth. However, the way you use transactions could violate one of the criteria. A misbehavior is not when a database will rollback if you throw an Exception when in fact it should only be a warning. Conclusion is:
you can rely on the ACID criteria the transactional system complies to*
Spring Framework transaction abstraction
Lets get specific and take Spring as a framework that can help you take control of the database transactional system. Spring is not the actual transactional system but it exposes an interface, that perfectly integrates with different transactional systems and it is called Spring Framework Transaction abstraction.
To get started you need to:
define the correct PlatformTransactionManager implementation (usually through dependency injection)
use the TransactionStatus interface to control transaction execution and query transaction status
The Spring transactional abstraction offers a lot of flexibility when it comes to controlling the transactional system. The implementation you choose must be a trade off between how tightly coupled you want/need to be to Spring’s transaction infrastructure and the need to use a non-invasive lightweight container which has less impact on application code. In this regard you need to choose between:
programmatic transaction management in Spring
declarative transaction management in Spring (XML or annotation based approach)
You can check out the differences in more detail in the Spring documentation. And a few words on how to chose between them is mentioned here.
Some general advice when using Spring transactions:
You are strongly encouraged to use the declarative approach to rollback, if at all possible. Spring docu
When using proxies, you should apply the @Transactional annotation only to methods with public visibility. If you do so on other access modifiers(protected, private or package-visible) methods, no error is raised but the annotated method does not exhibit the configured transactional settings. Spring docu
Spring recommends that you only annotate concrete classes (and methods of concrete classes), as opposed to annotating interfaces. Spring docu
@Transactional annotation on the method of the same class takes precedence (are more important) over the transactional settings defined at the class level.Spring docu
* of course, unless you need to debug exactly that and find out an enterprise ready system has bugs – bad luck…
To be continued…
Or just skip to a blog post I found recently written by Marco Behler.
Yup and I am very happy about it. The fist month back to code is almost over and I learned quite some stuff, 24 points to be exact, ’cause I’m keeping track. I should maybe mention some of them in another post. For now, this post is about something else, something I am wanting to pick up since some time but ALWAYS found a reason why not. Well, this time I should be out of ‘why not’ reasons and just do it: work on a personal projects.
Last year I started flirting with Golang, ah… just for the sake of it (another postponed thing). And I actually did some problem solving on HackerRank to get started. Then, I also read a super interesting survey result, also from HackerRank, which talks about what employers want and what developers can do. That is where I got the idea to also go back do some Javascript (also because my project need at least a basic frontend).
Here I am, shaping up a project idea, more useful than fun, more for learning than being useful. But that is to be decided later… what it will become.
Some things are certain:
Functionality
search & autocomplete
suggest a new entry
admin dashboard with CRUD actions
2 types of users: admin and public
API (maybe) for further features like – statistics, graphics, similarity…
Stack
backend: Golang
frontend: Javascript
This is my commitment to see it through basically! I will also soon post my git repo when it is up. Oh oh and did I mention, the topic is: funding and women in STEM!
Updated on 15.08.2021: This project did not pick up. I leave this here to showcase the struggle I have when I want to work on some personal coding projects. I want it to showcase that you do not need to do extra coding projects in your free time to be good at coding.
I had the opportunity to give an interview for the magazine WOMAN regarding the topic of Impostor Syndrome. The article is only in German and was not available online so I uploaded it here for who is interested to read it. Credits to Angelika Strobl who interviewed me and wrote the article. Enjoy!
The Linked Data Lexicography for High-End Language Technology (LDL4HELTA) project was started in cooperation between Semantic Web Company (SWC) and K Dictionaries. LDL4HELTA combines lexicography and Language Technology with semantic technologies and Linked (Open) Data mechanisms and technologies. One of the implementation steps of the project is to create a language graph from the dictionary data.
The input data, described further, is a Spanish dictionary core translated into multiple languages and available in XML format. This data should be triplified (which means to be converted to RDF – Resource Description Framework) for several purposes, including enriching it with external resources. The triplified data needs to comply with Semantic Web principles.
To get from a dictionary’s XML format to its triples, I learned that you must have a model. One piece of the sketched model, representing two Spanish words that have senses that relate to each other, is presented in Figure 1.
Figure 1: Language model example
This sketched model first needs to be created by a linguist who understands both the language complexity and Semantic Web principles.
Language is very complex. With this, we all agree! How complex it really is, is probably often underestimated, especially when you need to model all its details and triplify it.
So why is the task so complex?
To start with, the XML structure is complex in itself, as it contains nested structures. Each word constitutes an entry. One single entry can contain information about:
Pronunciation
Inflection
Range Of Application
Sense Indicator
Compositional Phrase
Translations
Translation Example
Alternative Scripting
Register
Geographical Usage
Sense Qualifier
Provenance
Version
Synonyms
Lexical sense
Usage Examples
Homograph information
Language information
Specific display information
Identifiers
and more…
Entries can have predefined values, which can recur but their fields can also have so-called free values, which can vary too. Such fields are:
Aspect
Tense
Subcategorization
Subject Field
Mood
Grammatical Gender
Geographical Usage
Case
and more…
As mentioned above, in order to triplify a dictionary one needs to have a clearly defined model. Usually, when modeling linked data or just RDF it is important to make use of existing models and schemas to enable easier and more efficient use and integration. One well-known lexicon model is Lemon. Lemon contains good pieces of information to cover our dictionary needs, but not all of them. We started using also the Ontolex model, which is much more complex and is considered to be the evolution of Lemon. However, some pieces of information were still missing, so we created an additional ontology to cover all missing corners and catch the specific details that did not overlap with the Ontolex model (such as the free values).
An additional level of complexity was the need to identify exactly the missing pieces in Ontolex model and its modules and create the part for the missing information. This was part of creating the dictionary’s model which we called ontolexKD.
As a developer you never sit down to think about all the senses or meanings or translations of a word (except if you specialize in linguistics), so just to understand the complexity was a revelation for me. And still, each dictionary contains information that is specific to it and which needs to be identified and understood.
The process used in order to do the mapping consists of several steps. Imagine this as a processing pipeline that manipulates the XML data. UnifiedViews is an ETL tool, specialized in the management of RDF data, in which you can configure your own processing pipeline. One of its use cases is to triplify different data formats. I used it to map XML to RDF and upload it into a triple store. Of course, this particular task can also be achieved with other such tools or methods for that matter.
In UnifiedViews the processing pipeline resembles what appears in Figure 2.
Figure 2: UnifiedViews pipeline used to triplify XML
The pipeline is composed out of data processing units (DPUs) that communicate iteratively. In a left-to-right order, the process in Figure 2 represents:
A DPU is used to upload the XML files into UnifiedViews for further processing;
A DPU which transforms XML data to RDF using XSLT. The style sheet is part of the configuration of the unit;
The .rdf generated files are stored on the filesystem;
And, finally, the .rdf generated files are uploaded into a triple store, such as Virtuoso Universal server.
Complexity increases also through the URIs (Uniform Resource Identifier) that are needed for mapping the information in the dictionary, because with Linked Data any resource should have a clearly identified and persistent identifier! The start was to represent a single word (the headword) under a desired namespace and build on it to associate it with its part of speech, grammatical number, grammatical gender, definition, and translation – just to begin with.
The base URIs follow the best practices recommended in the ISA study on persistent URIs following the pattern:http://{domain}/{type}/{concept}/{reference}.
An example of such URIs for the forms of a headword is:
If the dictionary contains two different adjectival endings, as with entendedor which has different endings for the feminine and masculine forms (entendedora and entendedor), and they are not explicitly mentioned in the dictionary then we use numbers in the URI to describe them. If the genre would be explicitly mentioned the URIs would be:
In addition, we should consider that the aim of triplifying the XML was for all these headwords with senses, forms, and translations, to connect and be identified and linked following Semantic Web principles. The actual overlap and linking of the dictionary resources remains open. A second step for improving the triplification and mapping similar entries, if possible at all, still needs to be carried out. As an example, let’s take two dictionaries, say German, which contain a translation into English, and an English dictionary which also contains translations into German. We get the following translations:
Bank – bank – German to English
bank – Bank – English to German
The URI of the translation from German to English was designed to look like:
In this case both represent the same translation but have different URIs because they were generated from different dictionaries (mind the translation order). These should be mapped so as to represent the same concept, theoretically, or should they not?
The word Bank in German can mean either a bench or a bank in English. When I translate both English senses back into German I get the word Bank, but I cannot be sure which sense I translated unless the sense id is in the URI, hence the SE00006110 and SE00006116. It is important to keep the order of translation (target-source) but later map the fact that both translations refer to the same sense, the same concept. This is difficult to establish automatically. It is hard even for a human sometimes.
One of the last steps of complexity was to develop a generic XSLT which can triplify all the different languages of this dictionary series and store the complete data in a triple store. The question remains: is the design of such a universal XSLT possible while taking into account the differences in languages or the differences in dictionaries?
The task at hand is not completed from the point of view of enabling the dictionary to benefit from Semantic Web principles yet. The linguist is probably the first one who can conceptualize “the how to do this”.
As a next step we will improve the Linked Data created so far and bring it to the status of a good linked language graph by enriching the RDF data with additional information, such as the history of a term or additional grammatical information etc.
In July 2016 I had the opportunity to represent the company I work for, Semantic Web Company, at Connected Data London. I had a 15 minutes slot to present some client success stories with connected data. At the conference I also actively represented PoolParty, our Software Suite, at the official stand offered to partners and sponsors.
I found London to be somehow “smaller” than the expectations floating around it. However, the people I interacted with (not at the conference) gave me immediately a very international flair of the city, more than in Vienna.
In the opening of the event David Meza presented how it is to use RDF and graph technologies at NASA. I was really happy to attend his session and to meet him in person.
The agenda of the first ever event is still online.
Quite some time past since the last Women Techmakers Vienna event. I still get positive feedback and even more: people ask me to upload the content of the Impostor Syndrome workshop online. It is always great to see how helpful such information is. The workshop helped me a great deal!
So, here it goes, find the resources of the workshop right here!
The materials for this workshop were inspired by the Ada Initiative. Find the original information on their website. This content was slightly changed to fit the Women Techmakers Vienna conference. (the main content remained the same).
There are several resources available fro the workshop. Find all the materialshere.
Available materials are:
A handout of the workshop explains in general what impostor syndrome is and how to overcome it. It also contains other references.
The workshop was created in such a way that it can be easily taken over and presented in other workshops/conferences as well. A facilitator guide example can be found also.
There were 3 exercises conducted in the workshop. Their description can also be found in the above link.
Thank you to the ones who attended and thank you to the ones who are interested in this topic.
As an open data fan or as someone who is just looking to learn how to publish data on the Web and distribute it through the Semantic Web you will be facing the question “How to describe the dataset that I want to publish?” The same question is asked also by people who apply for a publicly funded project at the European Commission and want to have a Data Management plan. Next we are going to discuss possibilities which help describe the dataset to be published.
The goal of publishing the data should be to make it available for access or download and to make it interoperable. One of the big benefits is to make the data available for software applications which in turn means the datasets have to be machine-readable. From the perspective of a software developer some additional information than just name, author, owner, date… would be helpful:
the condition for re-use (rights, licenses)
the specific coverage of the dataset (type of data, thematic coverage, geographic coverage)
technical specifications to retrieve and parse an instance (a distribution) of the dataset (format, protocol)
the features/dimensions covered by the dataset (temperature, time, salinity, gene, coordinates)
the semantics of the features/dimensions (unit of measure, time granularity, syntax, reference taxonomies)
To describe a dataset the best is always to look first at existing standards and existing vocabularies. The answer is not found looking only at one vocabulary but at several.
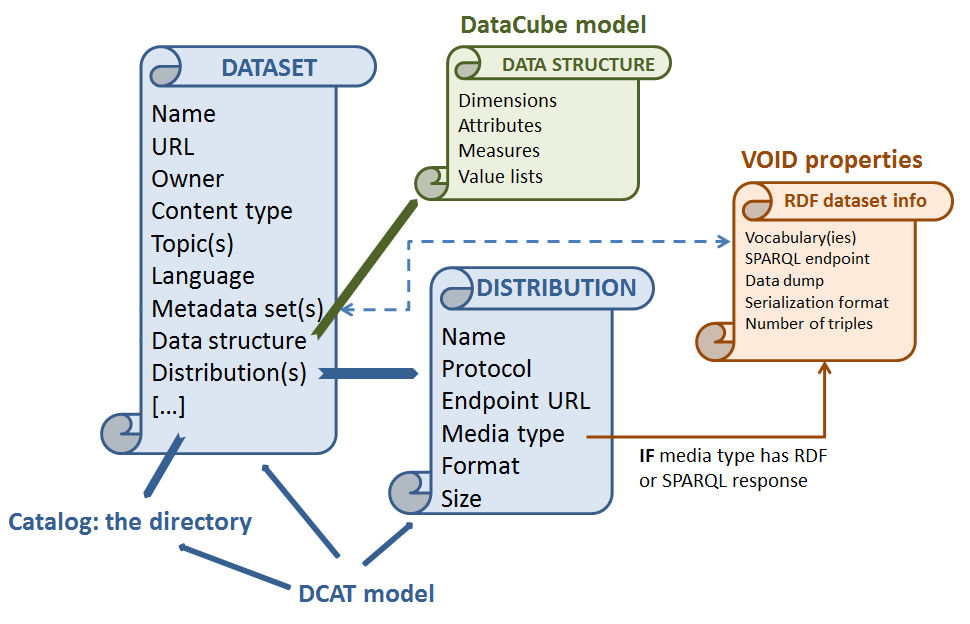
Data Catalog Vocabulary (DCAT)
DCAT is an RDF Schema vocabulary for representing data catalogs. It is an RDF vocabulary for describing any dataset, which can be standalone or part of a catalog.
Vocabulary of Interlinked Datasets (VoID)
VoID is an RDF vocabulary, and a set of instructions, that enable the discovery and usage of linked data sets. VOID is an RDF vocabulary for expressing metadata about RDF datasets.
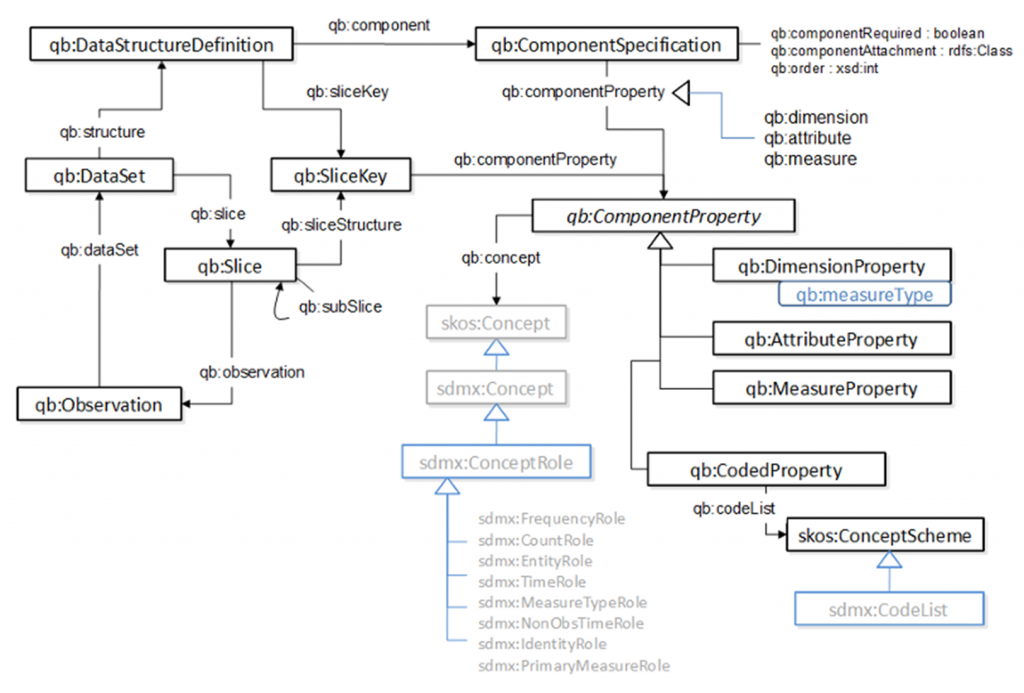
Data Cube vocabulary
Data Cube vocabulary is focused purely on the publication of multi-dimensional data on the web. It is an RDF vocabulary for describing statistical datasets.
Asset Description Metadata Schema (ADMS)
ADMS is a W3C standard developed in 2013 and is a profile of DCAT, used to describe semantic assets.
You will find only partial answers of how to describe your dataset in existing vocabularies while some aspects are missing or complicated to express.
Type of data – there is no specific property for the type of data covered in a dataset. This value should be machine readable which means it should be standardized, possibly to an URI which can be de-reference-able to a thing. And this ‘thing’ should be part of an authority list/taxonomy which is not existing yet. However one can use the adms:representationTechnique, which gives more information about the format in which a dataset is released. This points only to dcterms:format and dcat:mediaType.
Technical properties like – format, protocol etc.
There is no property for protocol and again these values should be machine-readable, standardized possibly to an URI.
VoID can help with the protocol metadata but only for RDF datasets: dataDump, sparqlEndpoint.
Dimensions of a dataset.
SDMX defines a dimension as “A statistical concept used, in combination with other statistical concepts, to identify a statistical series or single observations.” Dimensions in a dataset can therefore be called features, predictors, or variables (depending on the domain). One can use dc:conformsTo and use a dc:Standard if the dataset dimensions can be defined by a formalized standard. Otherwise statistical vocabularies can help with this aspect which can become quite complex. One can use the Data Cube vocabulary specifically qd:DimensionProperty, qd:AttributeProperty, qd:MeasureProperty, qd:CodedProperty in combination with skos:Concept and sdmx:ConceptRole.
Data provenance – there is the dc:source that can be used at dataset level but there is no solution if we want to specify the source at data record level.
In the end one needs to combine different vocabularies to best describe a dataset.
The tools out there used for helping in publishing data seem to be missing one or more of the above mentioned parts.
CKAN maintained by the Open Knowledge Foundation uses most of DCAT and doesn’t describe dimensions.
Dataverse created by Harvard University uses a custom vocabulary and doesn’t describe dimensions.
CIARD RING uses full DCAT AP with some extended properties (protocol, data type) and local taxonomies with URIs mapped when possible to authorities.
OpenAIRE, DataCite (using re3data to search repositories) and Dryad use their own vocabularies.
The solution to these existing issues seem to be in general, introducing custom vocabularies.
References:
Valeria Pesce, “How to describe a dataset. Interoperability issues”, Presentation at the Global Forum on Agricultural Research, 21.09.2015
I had the opportunity to hold a presentation about what I have been doing lately: a Web Application to show off the power of SPARQL. I turned my experience into an introduction of how to “Developing for the Semantic Web”.
Last week was the Google I/O Developer conference and Polymer 1.0 was presented. So finally my curiosity was sparked and I made some time to check it out a little bit. I was looking for a fast way to create a JAVA Web Application where I can use Polymer so I heard about how easy and fast Spring Boot is.
So voilà, my first JAVA Web App with Spring Boot and Polymer 1.0. You can clone it from Git and use it as a archetype – the Polymer files are included in the project already. (also for learning purposes). I used Maven to build the project, which is also easy. But one can also use Gradle.
The only issue I encountered was that the index.html was not displayed. After a bit of reading, in the Spring Boot docu you find:
Do not use the src/main/webapp directory if your application will be packaged as a jar…
By default Spring Boot will serve static content from a directory called /static (or /public or /resources or /META-INF/resources) in the classpath or from the root of the ServletContext.
Fast enough, I changed the folder name and it worked.